If you have ever dealt with binary data, then the chances are that you must have come across the term endianness at least once.
Let’s take a deeper dive and see how you can keep your bytes in order.
If you’re here for the code, then skip ahead to methods.
What is endianness?
Endianness is basically the sequential order in which bytes are organized in a word. Generally, the computer memory is byte addressable therefore it doesn’t care how the constituent bytes are organized.
“Endianness refers to the sequential order in which bytes are arranged into larger numerical values when stored in memory or when transmitted over digital links” Wikipedia
However, the processor often works with multiple bytes of data depending on its word length. For instance, a 64-bit CPU can process 8-byte data words. Hence, the ordering becomes important as any inconsistency will result in unexpected results.
So you might be wondering why can’t we just stick to the order in which most of us write a numeric value i.e. starting with the most significant byte(MSB) and ending with the least significant byte (LSB) also known as “Big-Endian” ordering. In fact, that is perfectly fine but as with most things in the computer industry, some vendors choose to go the other way. In those systems, the word starts with the LSB and ends with the MSB.
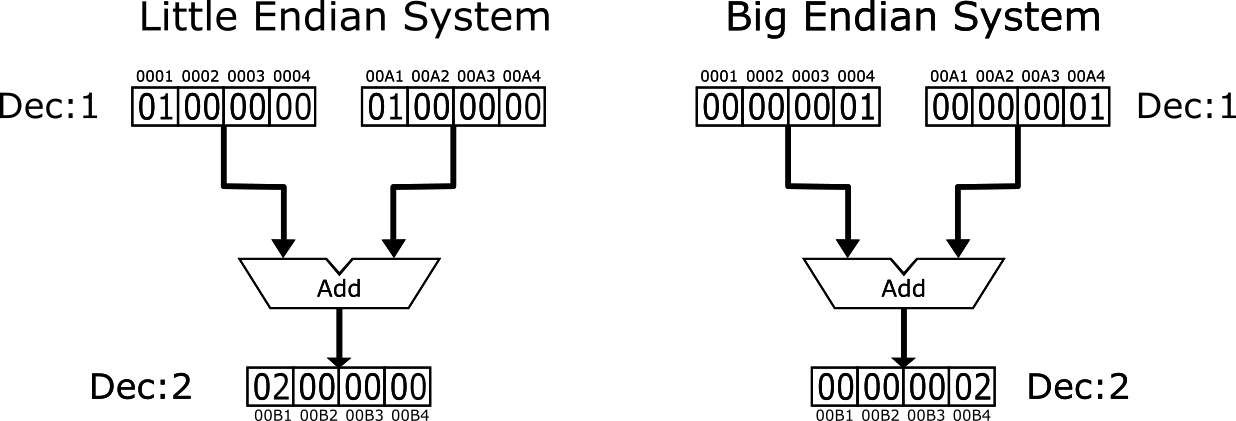
What determines the endianness of a system?
As we have seen earlier the memory(main memory) doesn’t care in what order the words are stored since all the bytes are individually addressed. Therefore it has got nothing to do with the endianness of the system.
The CPU, on the other hand, is designed in such a way that it expects the data words to be in a specific order. Hence, it determines the endianness in use.
The popular x86 architecture uses little-endian byte ordering.
Checking the endianness of your system
It is pretty easy to check the endianness of a system. Just see where the MSB of a value is in memory.
#include <iostream>
#include <cstdint> // uint16_t and uint8_t
using namespace std;
bool isBigEndian(){
uint16_t word = 1; // 0x0001
uint8_t *first_byte = (uint8_t*) &word; // points to the first byte of word
return !(*first_byte); // true if the first byte is zero
}
int main(){
cout << (isBigEndian()?"Big-Endian":"Little-Endian") << endl;
return 0;
}
Why should you care about endianness?
We are not writing assembly anymore then why are we concerned about such a low-level detail. Well, the compiler takes care of most of the heavy-lifting but there are certain cases where the developer’s attention is required. The following are the two common cases.
Handling binary files
Binary files have a standard software representation which may or may not match with the endianness of your system. Therefore it needs to be handled accordingly by the developer.
For instance, a JPEG file uses big-endian format with a word size of 16-bits.
Data transfer over a network
Here the network protocols define the endianness of the transmitted data so that multiple systems on the network can safely agree on the data being communicated. The developer has to make sure that it is maintained irrespective of the system.
In TCP/IP, big-endian ordering is used as a convention and it might vary depending on the application protocol.
Methods for handling endianness in C++
There are many ways in which you can switch between native and standard byte ordering. A few of the common methods are listed below:
Use the socket programming API
One of the easiest ways to convert between byte orderings is to use the socket programming API which comes with a set of handy functions
uint16_t htons(uint16_t hostshort)- converts host byte order to network byte order.uint16_t ntohs(uint16_t hostshort)- converts network byte order to host byte order.
The network byte order is always big-endian by convention.
If your system is little-endian (host byte order) the above functions will perform the necessary byte swapping otherwise they just return the same value.
Similarly, htonl and ntohl handles a 32-bit word.
#include <cstdio>
#include <arpa/inet.h> // htonl
#include <cstdint> // uint32_t and uint8_t
/*
The expected output on a little-endian system:
00EEFFAA
AAFFEE00
*/
using namespace std;
void show_memory_representation(const uint8_t* firstbyte,const int length){
for(int i=0;i<length;++i){
printf("%.2X",*(firstbyte + i));
}
printf("\n");
}
int main(){
uint32_t hostlong = 0xAAFFEE00;
uint32_t netlong;
show_memory_representation((uint8_t*)&hostlong,sizeof(hostlong));
netlong = htonl(hostlong);
show_memory_representation((uint8_t*)&netlong,sizeof(netlong));
return 0;
}
Use Boost.Endian library
The Boost library offers a rich set of function to manipulate the endianness of integers and user-defined types.
#include <iostream>
#include <cstdio>
#include <cstdint> // uint8_t,uint32_t
#include <boost/endian/conversion.hpp> // order, endian_reverse
using namespace std;
/*
Output on a little endian system:
Little-Endian
Native order:
DDCCBBAA
Native order reversed:
AABBCCDD
Native order converted to big endian:
AABBCCDD
Native order converted to little endian:
DDCCBBAA
Little-endian order converted to native:
DDCCBBAA
Big-endian order converted to native:
DDCCBBAA
*/
void show_memory_representation(const uint8_t* firstbyte,const int length){
for(int i=0;i<length;++i){
printf("%.2X",*(firstbyte + i));
}
printf("\n");
}
int main(){
// testing the endianness
if(boost::endian::order::native == boost::endian::order::big){
cout << "Big-Endian" << endl;
}else if(boost::endian::order::native == boost::endian::order::little){
cout << "Little-Endian" << endl;
}
// word is in native byte order
uint32_t word = 0xAABBCCDD;
cout << "Native order:" << endl;
show_memory_representation((uint8_t*)&word,sizeof(word));
// reverses the current order
uint32_t reversed_word = boost::endian::endian_reverse(word);
cout << "Native order reversed:" << endl;
show_memory_representation((uint8_t*)&reversed_word,sizeof(reversed_word));
// converts native order to big endian
uint32_t big_word = boost::endian::native_to_big(word);
cout << "Native order converted to big endian:" << endl;
show_memory_representation((uint8_t*)&big_word,sizeof(big_word));
// converts native order to little endian
uint32_t little_word = boost::endian::native_to_little(word);
cout << "Native order converted to little endian:" << endl;
show_memory_representation((uint8_t*)&little_word,sizeof(little_word));
// converts little endian order to native
uint32_t native_word = boost::endian::little_to_native(little_word);
cout << "Little-endian order converted to native:" << endl;
show_memory_representation((uint8_t*)&native_word,sizeof(native_word));
// converts big endian order to native
native_word = boost::endian::big_to_native(big_word);
cout << "Big-endian order converted to native:" << endl;
show_memory_representation((uint8_t*)&native_word,sizeof(native_word));
return 0;
}
I think the example program is pretty much self-explanatory and Boost.Endian comes with a lot of bells and whistles. Therefore covering all of them in a single blog post is impossible. You can find the official documentation here for more details.
Build your own container
If you need even more control, you could just use a standard C++ union to roll out your own.
Here, we are using the property of a union which shares the allocated memory between all of its elements. Which means it can only hold one of its non-static data members at any given time.
We will also use some operator overloading to make things simpler.
#include <iostream>
#include <cstdint> //uint8_t, uint32_t
using namespace std;
/*
The expected output on a little-endian system:
Actual memory representation:
DDCCBBAA
Expecting little-endian, storing as big-endian
AABBCCDD
Expecting little-endian, storing as little-endian
DDCCBBAA
Expecting big-endian, storing as big-endian
DDCCBBAA
Expecting big-endian, storing as little-endian
AABBCCDD
*/
enum ENDIANNESS{
little,
big
};
template<typename T,ENDIANNESS from, ENDIANNESS to>
struct Word{
/* anonymous union makes sure that the data and
** byte[] occupy the same memory location
*/
union{
T data;
uint8_t byte[sizeof(T)];
};
uint8_t& operator[](int i){
if(from == to){
return byte[i];
}else{
/* flip the order only if the source and destination has
** different ordering
*/
return byte[sizeof(T) - i - 1];
}
}
};
// a helper function to show how the actual memory representatiom
void show_memory_representation(const uint8_t* firstbyte,const int length){
for(int i=0;i<length;++i){
printf("%.2X",*(firstbyte + i));
}
printf("\n");
}
int main(){
Word<uint32_t,ENDIANNESS::little,ENDIANNESS::big> w;
Word<uint32_t,ENDIANNESS::little,ENDIANNESS::little> w1;
Word<uint32_t,ENDIANNESS::big,ENDIANNESS::big> w2;
Word<uint32_t,ENDIANNESS::big,ENDIANNESS::little> w3;
// our data source which will be using the system endianness in this case
uint32_t source = 0xAABBCCDD;
cout << "Actual memory representation:" << endl;
show_memory_representation((uint8_t*)&source,4);
// to iterate through the data source (could be a file pointer)
uint8_t *ptr = (uint8_t*)&source;
for(int i=0;i<4;++i){
w[i] = *(ptr + i);
w1[i] = *(ptr + i);
w2[i] = *(ptr + i);
w3[i] = *(ptr + i);
}
cout << "Expecting little-endian, storing as big-endian" << endl;
show_memory_representation((uint8_t*)&w.data,4);
cout << "Expecting little-endian, storing as little-endian" << endl;
show_memory_representation((uint8_t*)&w1.data,4);
cout << "Expecting big-endian, storing as big-endian" << endl;
show_memory_representation((uint8_t*)&w2.data,4);
cout << "Expecting big-endian, storing as little-endian" << endl;
show_memory_representation((uint8_t*)&w3.data,4);
return 0;
}
You could use it with pretty much any built-in or user-defined datatype. And by no means, this is the best possible implementation out there. This is just something I came up with when I had a requirement. If you know a better way of implementing it, feel free to let me know in the comments.
Thank you for reading! 😀